Apache Camel supports a mapped diagnostic context which can be used to improve log entries, but also there is a log component which makes it easier to create log entries. Together they can be used to create foundations of activity monitoring without need to deploy another tool or database.
Logging anti patterns
First of all let’s go throught logging anti patterns described years ago by Gojko Adzic. They are really good and shows how to avoid common problems:
- Single log file for all people
- Lack of hierarchy in log categories (that’s mine idea)
- Incomplete data in entries (covers also one information split to multiple entries)
- Different separators in single line
- Inconsistent log entry format (covers also inconsistent log entry format)
- Multi-line entries
- Populating log after the action
Let describe comon mistakes we can do with Camel and how these anti patterns can look in our case. My thoughts can be really close to Gojko, but I’ll try to show you where you can meet these anti patterns on Java ground.
Single log file
As usual log file can be used by different people for diagnostic - eg. database administrators are not interested in all java stuff we do. Message processing, filtering and so on. They want to see query, their parameters and execution time. Nothing else. System administrators are another group which are forced to read dozen of lines to find exception with message ‘Too many open files’. IOExceptions are definitely category important for these people more than surrounding. We can leverage existing features from logging framework to create advanced filters to route logs.
Lack of hierarchy in log categories
Many libraries use a single log category or only few to do logging. That’s completly wrong idea. Let take a look for Atomikos. By default all log are produced by ‘atomikos’ category. Even if you are interested in connection pooling tracing you are forced to see almost all events happened from begining of transaction to it’s end. In case of Apache Camel and middleware - consider:
- Usage of own categories, different than a framework which will reflect your mediation process logic, not technical details. Even if you are genius programmer you can be confused by log entries not connected with any process stage.
- Be sure that all events produced by your processors, classes and context or route go to same log hierarchy - eg. org.code_house.esb.sap.finance, instead of “processor”, “org.myjavapackage” and so on. Be consistent on that.
- Do not trust a thread name and do not use it as the category. Name of it can be changed by camel core change or component update.
Camel components have a proper packages and you can easily get rid of statements unnecessary for you.
Incomplete data in entries
That’s I think most common mistake. The best example is Hibernate and SQL parameters logging. To get all data related to SQL query exceution and parameter binding we all are forced to use two totally different categories which are not in same hierarchy. If you are happy with setting TRACE level for org.hibernate package you can skip this example. If you have all parameters and SQL query put it together to log stream. Even if line will be insane long you will be sure that you see parameters for this SQL query, not two different.
Different separators in single line
I like to have a log with brackets, pipes and dots. This is so geeky. You look like guy who can see matrix and knows what is happening. Actually you do, but text processing tools are not so smart as we. Parsing is as complex as log pattern is. So don’t use too complex patterns in production and try to use singular separator. Some commercial tools require a special log format. Cook it for this tool in separate file or use different appender. Even if it is redundant. Keep main log clear and not affected by specific format which cuts 50% of diagnostic information or make it harder to read.
Multi-line entries
Just imagine that your SQL query have 5 lines. Not too much, isn’t? But what’s when you have a 200KB (or more) payload? Your log will grow quicker than disk size. Basically multi line entries can make parsing harder, but also makes log file longer and harder to read. If you need to keep messages don’t do that in log file. That’s not place for that. Reuse auditing features from ServiceMix NMR or archive ActiveMQ store. You can also build your own mechanism as well if these are not sufficient using asynchronous Wire Tap pattern.
Populating log after the action
Latest anti-pattern - remember that logs are produced by code should prelude a operation. Not other - otherwise log entry before exception will point to mediation which was fine or your will be not able to say what happened with given message. If you are against this point remember to notify people about your logging behavior. Most of them expect that log stream allows to see path before error occured (I received message with given ID), error (exception during message transofrmation) and recovery actions (message moved to dead letter).
Best practices of logging with Apache Camel
 Apache Camel uses slf4j as logging library. It’s a generic facade to many different logging libraries. You don’t have to use it in your project directly, you still can use Log4j or commons-logging, but it’s always the better to have less dependencies and clean classpath. I will not complain about ideas behind slf4j here, just point to your nous and let you nod. :)
Apache Camel uses slf4j as logging library. It’s a generic facade to many different logging libraries. You don’t have to use it in your project directly, you still can use Log4j or commons-logging, but it’s always the better to have less dependencies and clean classpath. I will not complain about ideas behind slf4j here, just point to your nous and let you nod. :)
Name your elements
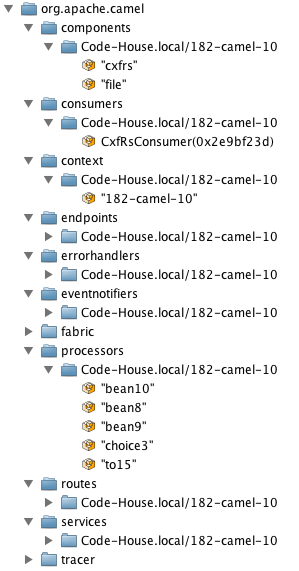
If you going to live with your middleware you should know what happens when. Especially that you will have difficulty to access production environment with your lovely IDE and debugger. That’s why at least camel context should have a name. From runtime management point of view it should always have a given name. If you have a JMX console to do some administrative operations than 182-camel-10 is confusing. Just see image on right side and try to say what the following processors do. Sure, you can do that by walking whole JMX tree.
Use a Mapper Diagnostic Context (MDC)
MDC is an bridge from your application to logging framework. You can set some application specific variables and then re-use them to create rich log format or distinct log files by application id (yeah, it seems like missing feature in Tomcat for me too). This feature is disabled by default for Camel but it might be easily turned on. Let’s have a look on MDC variables set by Apache Camel:
- breadcrumbId
- exchangeId
- messageId
- correlationId
- routeId
- camelContextId
- transactionKey
Each variable from this list can be used in combination with log format or appender. For example if you have all variables set correctly you can use this format: [plain] log4j.appender.out.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %X{camelContextId} %X{bundle.version} | %X{routeId} %X{exchangeId} | %m%n [/plain] And you will get following line produced: [plain]23:56:12,158 | INFO | database-batch 2.8.0.fuse-01-06 | jms-inbound-hr | ID-Code-House-local-60526-1330335502920-25-33 | Received message[/plain]
For me it’s still do not look like something easy to read, that’s why I introduce appender: [plain] log4j.appender.integrationProcess=org.apache.log4j.sift.MDCSiftingAppender log4j.appender.integrationProcess.key=camelContextId log4j.appender.integrationProcess.default=unknown log4j.appender.integrationProcess.appender=org.apache.log4j.RollingFileAppender log4j.appender.integrationProcess.appender.layout=org.apache.log4j.PatternLayout log4j.appender.integrationProcess.appender.layout.ConversionPattern=%d{ABSOLUTE} | %-5.5p | %X{routeId} %X{bundle.version} | %X{exchangeId} | %m%n log4j.appender.integrationProcess.appender.file=${karaf.data}/log/mediation-$\{camelContextId\}.log log4j.appender.integrationProcess.appender.append=true log4j.appender.integrationProcess.appender.maxFileSize=1MB log4j.appender.integrationProcess.appender.maxBackupIndex=10
log4j.category.com.mycompnany.camel_toys.hr=INFO, integrationProcess [/plain] By default, when the camelContextId is not set log entries will be appended to file data/log/mediation-unknown.log. But for these which have a context ID it will look much better (file mediation-database-batch.log): [plain] 00:38:42,386 | INFO | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-67 | Received message with business key XYZ. 00:38:43,387 | INFO | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-67 | Saving message in database 00:38:44,388 | INFO | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-67 | Processing of message with business key XYZ complete. 00:38:44,389 | INFO | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-68 | Received message with business key ZYX. 00:38:45,390 | INFO | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-68 | Saving message in database 00:38:45,391 | ERROR | jms-inbound-hr 2.8.0.fuse-01-06 | ID-Code-House-local-51055-1330383822002-4-68 | Processing of message with business key ZYX failed. [/plain] As you see these log entries contains only a process specific informations and they are not influenced by technical details. A category is skipped because it is not relevant in this context (it still for developer logging but not here). Also you don’t have to extract a business key. You might use a breadcrumbId header or correlationId property. Before you will start using MDC be aware that the property names might be changed because issue CAMEL-5047 Clean up MDC property names. This configuration was tested with Camel up to 2.9 release. The bundle.version property is set by pax-logging, not Camel and I treat it as a mediation process version. Log4j sift appender is a wrapper so it will work also with syslog or an database appender.
Embedded processors
Embedded processors are something common in java DSL. If you use them your category will contain a dollar sign (my.company.RouteBuilderExt$1). Then you should not implement too complex logic in it. If you need do something more than glue strings or set header and you wish to log that - then create a separate class and remember about log category hierarchy and do not use a RouteBuilder log category. Processor logic is deeper than the route builder’s and you do some specific task. Separate it. Keep same approach for AggreagatorStrategy and org.apache.camel.spi extensions.
[java] package com.mycompnany.camel_toys.hr; public class Route extends RouteBuilder {
Log log = LogFactory.getLog(Route.class);
@Override public void configure() throws Exception { from("") .onException(Exception.class) .process(new Processor() { @Override public void process(Exchange exchange) throws Exception { org.apache.camel.Message out = exchange.getOut(); out.setHeader(org.apache.cxf.message.Message.RESPONSE_CODE, new Integer(500)); log.error(“Unexpected exception”, exchange.getException()); } } }) .end() .to("") } } [/java] It’s better to have: [java] package com.mycompnany.camel_toys.hr; // or .processor if we have few or logic is complex public class ExceptionProcessor implements Processor { // slf4j! private Log log = LoggerFactory.getLogger(ExceptionProcessor.class); @Override public void process(Exchange exchange) throws Exception { org.apache.camel.Message out = exchange.getOut(); out.setHeader(org.apache.cxf.message.Message.RESPONSE_CODE, new Integer(500)); log.error(“Unexpected exception”, exchange.getException()); } } [/java]
Usage of camel-log component
Most of use this component in more or less proper way. For example: [java] onException(Exception.class) .log(“Unexpected exception ${exception}”) .end() [/java] By default your logging category will be set to route id (eg route4, route5 etc) which will obviously not help in detecting the issues. Also log level is not present so it’s set by default to INFO. A proper usage is: [java] onException(Exception.class) // see, I have here a same category as route builder because it’s on same level .log(LoggingLevel.ERROR, “com.mycompnany.camel_toys.hr”, “Unexpected exception ${exception}”) .end() [/java]
Quick summary
It’s too late to continue this blog entry, but I hope it will be useful for all of you. Remember - be a reasonable. Use short log entries for business activity monitoring and keep them far from technical details. A statement “Rejecting message because validation error” is sufficient for 95% of people. The remaining 5% is involved in development but for these you have a separate log. :)
I hope you like the idea of best practices and you would like to see more similar entries. If you feel yourself more experienced than I or you simply prefer a different approach and would like share your ideas - do that. It will be pleasure to discuss here or link to your reply on other blog.